Title: Yu. A. Malkov, D. A. Yashunin 2016.
HNSW: Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
Link: https://arxiv.org/abs/1603.09320
A-KNN 에서 좋은 성능을 보이고 있는 HNSW 라이브러리에 대한 논문입니다.
논문 내용에 워낙 생소한 개념도 많고, 한국어 자료가 없어서 애를 먹었습니다.
논문을 line by line 으로 설명하는 것은 어렵고, 관련 지식을 얻어가는 것 만으로 도움이 될 글이라고 생각합니다.
그래서 이번 포스팅은 Abstract 과 2. Related Work, 그리고 3. Motivation Section 을 주로 설명하려고 합니다.
논문 제목에서 알 수 있듯이 hnsw는 시간복잡도를 줄이고(efficient), 휴리스틱 알고리즘을 개선한(robust) A-KNN 알고리즘입니다.
[Abstract]
본 논문에서는 HNSW 의 NSW Graph 를 기반으로 A-KNN Search 에 대한 새로운 접근 방식을 제시합니다.
Hierarchical NSW 는 proximity graphs 의 계층들로 구성된 다층 구조를 구축합니다.
이 과정에서 계층(레이어)는 exponentially decaying probability distribution 을 사용하여 랜덤하게 선택됩니다.
한 계층에서의 그래프 생성은 이전에 NSW(Navigable Small World) 구조와 유사한 그래프를 생성합니다.
계층을 분리하여 상위 레이어부터 검색을 시작하면, NSW 에 비해 성능이 향상되고 시간복잡도도 O(logN) 이 가능합니다.
추가로 근접한 이웃을 선택하는 데 있어 개선된 휴리스틱 알고리즘을 추가로 사용하여 성능이 향상되고, 특히 cluster된 데이터의 경우 성능이 크게 향상됩니다.
성능 평가를 통해 해당 방법이 이전의 벡터기반 접근으로 SOTA를 달성한 오픈소스들 많이 능가(strongly outperform)할 수 있음을 입증했습니다.
[2. Related Work]
[2.1 Proximity graph techniques]
현재까지 연구된 Proximity graph를 활용한 KNN 방법은 근접 이웃 링크를 Delaunay graph를 통한 근사치로 구합니다.
Delaunay graph, 들로네 그래프는 무엇이냐, 하면 SW 알고리즘에서 최소한의 링크로 모든 점을 연결하는,
MST 를 떠올리시면 이해가 빠를 것 같습니다.
저는 아래 다크 프로그래머 님의 블로그를 통해 이해했습니다.
https://darkpgmr.tistory.com/96
들로네 삼각분할(Delaunay triangulation) & 보로노이 다이어그램(Voronoi diagram)
들로네 삼각분할(Delaunay Triangulation)과 보로노이 다이어그램(Voronoi diagram)이 무엇인지? 어디에 쓰이는지? 그리고 어떻게 구하는지에 대한 글입니다. 1. 참고 문헌(자료) 참고한 주요 자료들입니다.
darkpgmr.tistory.com
위와 같은 접근방식을 다른 k-ANN 기술에 비해 경쟁력을 발휘합니다.
그럼에도 불구하고 발견되는 해당 방법의 주요 단점은 아래와 같습니다.
1) the power law scaling of the number of steps with the dataset size during the routing process
1) 라우팅 프로세스 동안 데이터 세트 크기에 따른 단계 수의 power law scaling
데이터 크기가 클 수록 복잡도 증가
2) a possible loss of global connectivity which leads to poor search results on clustered data.
2) 전역 연결 손실 가능성이 있음. 클러스터링된 데이터에 대한 검색 결과가 좋지 않을 수 있음.
위 단점을 극복하기 위해 다양한 접근법이 제안되었고, 그 중에서도 NSW 라는 근접 그래프 k-ANN 방법론을 해당 논문에서 사용하게 되었습니다.
NSW 구조는 구성 단계에서 효율적으로 병쳘처리 할 수 있어 분산 검색 시스템에 적합한 선택입니다.
해당 방식은 일부 데이터셋에서 SOTA 를 달성했지만, 전체적으로 poly log 복잡성으로 인해 일부 저차원 데이터셋에서 여전히 심각한 성능저하를 보였습니다.
[2.2 Navigable small world models]
2.1에서 언급된 NSW 모델에 대해서 알아보겠습니다.
NSW 모델을 이해하기 위해서는 논문에 나와있듯이 세가지 단계의 흐름을 알면 됩니다.
1. 밀그램의 Small-world experiment
https://en.wikipedia.org/wiki/Small-world_experiment
Small-world experiment - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Experiments examining the average path length for social networks The "six degrees of separation" model The small-world experiment comprised several experiments conducted by Stanley Mi
en.wikipedia.org
밀그램 교수의 실험으로,
어떤 특정 네트워크 내에서 전혀 모르는 사이라도 6개 이하의 hop을 통해 연결될 수 있다는 것을 증명한 실험입니다.
실험 절차는 위 링크에 상세히 나와있습니다.
2. small-world network.
던컨 와츠와 그의 지도 교수 스티브 스트로가츠의 'Collective dynamics of small-world networks'이라는 제목의 논문으로 1998년 네이처지에 발표한 개념.
https://ko.wikipedia.org/wiki/%EC%9E%91%EC%9D%80_%EC%84%B8%EC%83%81_%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC
작은 세상 네트워크 - 위키백과, 우리 모두의 백과사전
ko.wikipedia.org
1의 실험을 좀 더 과학적으로 증명한 논문으로, 우리 일상생활에 존재하는 네트워크들에 실제로 작은 세상 네트워크가 존재하는 지를
세가지 네트워크(actor, 기지국, 뉴런 시냅스) 를 통해 증명하는 과정이 담겨있다고 합니다.
작은 세상 네트워크는 Regular network(평균 거리 ↑ + 밀집도 ↓) 와 Random network(평균 거리 ↓ + 밀집도 ↑) 의 중간에 위치하는
randomness 를 갖고 있어 평균거리는 짧고, 밀집도(clustering)는 높은 형태의 네트워크입니다.
3. Navigation in a small world - It is easier to find short chains between points in some networks than others.
https://pdodds.w3.uvm.edu/teaching/courses/2008-01UVM-295/docs/papers/2000/kleinberg2000a.pdf
1, 2 번 논문을 바탕으로 이제 Traverse, 순회하는 효율적인 model 에 대한 접근을 다룹니다.
그래프 구성 시에는 위에서 언급했던 들로네 그래프를 통해 효율적으로 그래프를 생성하고,
검색 시에는 기본적인 Greedy Search 에 종료조건을 추가하여 좀 더 효율적인 KNN 검색을 가능하게 합니다.
그러나 2.1 섹션에서도 언급되었듯이 해당 방법론 NSW 는 poly log 만큼의 복잡도를 갖고 있어 여전히 성능이 좋지 않다고 합니다.
[3. Motivation]
이제 NSW에서 착안하여 추가 아이디어(레이어 추가)를 하는 과정에 대해 정리한 부분입니다. 이 부분도 제가 이해한대로만..-_-;;;
NSW + Hierarchical layer 를 추가하는 것. 이것이 HNSW 의 전부입니다.
논문의 아래 이미지가 잘 설명해주고 있습니다.
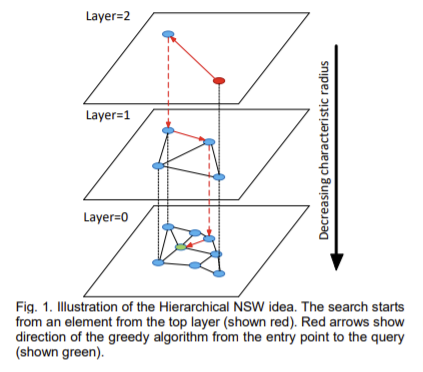
계층구조를 적용하는 것은 https://arxiv.org/pdf/0709.0303.pdf 논문의 zoom out/in 방법을 사용합니다.
zoom out (Layer=2 혹은 최대 레이어) 하여 해당 레이어에서, entry point 에서 시작하여 query 와 가장 가까운 이웃을 찾고,
더 이상 근접한 이웃이 없으면 하위 레이어로 이동하여 검색을 합니다.
zoom in 한 Layer=0 에서 가장 가까운 이웃을 찾고 답을 출력합니다.
이 때 사용하는 개념에는 skip list 와 검색 시 휴리스틱 알고리즘이 있습니다.
skip list 는,, 정확히 이해하지는 못했지만 아래 블로그를 참고하시면 좋을 것 같고,
https://www.pinecone.io/learn/hnsw/
Hierarchical Navigable Small Worlds (HNSW) | Pinecone
Demystifying and experimenting with HNSW for vector search.
www.pinecone.io
휴리스틱 알고리즘은 Algorithm 4 를 참고하시면 됩니다.
논문에 써있기로 Algorithm 3 의 단순한 검색보다 Algorithm 4 의 개선된 휴리스틱 알고리즘이 성능이 훨씬 좋다고 합니다.
여기서, 레이어의 갯수는 Abstract 에서 언급했듯 exponentially decaying probability distribution 를 통해 정해집니다.
또한, hnsw 방법의 정확도, 속도를 결정하는 값으로 구성 시에는 efConstruction, 검색 시에는 ef parameter가 있습니다.
ef 는 주변 이웃을 담고있는 priority queue 로, k ~ dataset 사이즈 만큼으로 설정할 수 있습니다.
적게 잡으면 정확도는 떨어지지만 속도가 빠르고, 값을 크게 설정하면 정확도는 높아지지만 속도가 느려지는 trade-off 관계입니다.
그 외 자세한 parameter 설명은 hnswlib github 페이지에 있습니다.
https://github.com/nmslib/hnswlib/blob/master/ALGO_PARAMS.md
GitHub - nmslib/hnswlib: Header-only C++/python library for fast approximate nearest neighbors
Header-only C++/python library for fast approximate nearest neighbors - GitHub - nmslib/hnswlib: Header-only C++/python library for fast approximate nearest neighbors
github.com
[4.2 Complexity analysis]
검색은 O(logN)
구성은 O(NlogN) 입니다.
[5 PERFORMANCE EVALUATION]
평가자료가 논문에 잘 나와있지만,
ANN 관련 모든 방법론에 대해 dataset 별로 성능을 정리한 github 페이지가 더 도움이 되었습니다.
이 페이지에서 보면 hnsw 방법론이 대부분의 dataset 에서 Top-5에 들 정도로 좋은 성능을 보인 것을 알 수 있습니다.
이외 ANN 으로 유명한 방법론인 스포티파이의 Annoy, ScaNN 등과 비교해도 좋은 성능을 보이고 있습니다.
https://github.com/erikbern/ann-benchmarks
GitHub - erikbern/ann-benchmarks: Benchmarks of approximate nearest neighbor libraries in Python
Benchmarks of approximate nearest neighbor libraries in Python - GitHub - erikbern/ann-benchmarks: Benchmarks of approximate nearest neighbor libraries in Python
github.com
마지막으로,
리서치 하면서 추가로 도움되었던 'KNN is dead' 컬럼 링크를 첨부합니다.
해당 컬럼의 저자도 hnsw를 애정한다고 얘기하고 있습니다.
성능 평가에서도 380배 속도가 향상되었으며 KNN 정답의 99.3% 를 커버할 정도로 성능저하 이슈도 없다고 정리하고 있습니다.
https://pub.towardsai.net/knn-k-nearest-neighbors-is-dead-fc16507eb3e
KNN (K-Nearest Neighbors) is Dead!
Long live ANNs for their whopping 380X speedup over sklearn’s KNN while delivering 99.3% similar results.
pub.towardsai.net
제 글을 통해 논문 이해하는 데 조금이라도 도움이 되셨길 바라며 정리 마치겠습니다.

댓글